For the last 10 days I've been fixing minor quirks in Humbug as they arise, but I've really been focused on AIFPL. I'm even more excited about it than before, but the inability of LLMs to count symbols correctly is a little challenging.
AIFPL - compiler edition
One of the more interesting developments just over a week ago was builing a simple compiler and bytecode VM for AIFPL. I got a simple 1-pass compiler running in about 4 days, and passing all my regression tests at the time. The results were impressive! The bytecode version, on average runs 12x faster than the interpreter on a benchmark test that Claude threw together for me. Importantly, it also compiled really fast, so even compiling and running a program once was often only slightly slower (about 10-20%) than just interpreting. That meant it was a good candidate for interactive tool use where an AI is building and running new code.
This aspect is really important and reminds me of some thinking by Niklaus Wirth in which he removed a more efficient algorithm in an Oberon compiler because while it was faster in complex cases, it was slower in the majority of quite simple ones. AIFPL will be guided by similar thinking, at least for interactive work!
I spent the entire weekend building 2 different 2-pass compilers and then discarding both of them because they had significant design flaws. I'd not built a Lisp-like compiler before so didn't know how to challenge assumptions from the LLM. While frustrating, and burning a lot of API tokens, I learned more in 2 days than I probably would have in 2 months previously.
What did come out of this, however, was me realizing I'd misunderstood special forms slightly and I corrected both the interpreter and 1-pass compiler to correct these. That then let me simplify all the builtin functions and suddenly everything looks much more clean!
For now, at least, I'm going to keep the interpreter updated because it's a good point of reference and doesn't take a lot of maintenance work because Claude is doing most of it!
My final realization in this hackathon was that the match operator is pure syntactic sugar and could be completely eliminated by a "desugaring" pass that did a source-to-source rewrite that lowers the main AIFPL into a simplified form.
Probably safe to say this last idea came from a paper I read 30 years ago: Realistic Compilation by Program Transformation
My 1-pass compiler became a 2-pass compiler anyway, but not in the way I'd expected.
Alist rework
One other outcome from this was to realize that my previous alist special form was confusing LLMs more often than not.
Previously we'd have:
(alist ("a" 23) ("b" 25) ("c" 98))But that means alists don't behave like lists and that's weird.
We now have a more conventional-looking, and less surprising form:
(alist (list "a" 23) (list "b" 25) (list "c" 98))It compiles exactly the same way and isn't that much more typing.
Alists are going to be a big part of AIFPL, however, just as dictionaries are in Python!
LLMs can't count parens (again)
For the last few days I've been trying to build the core of a project planning tool. As I want AIs to help with this problem I decided to code in AIFPL (or rather, have Claude code it in AIFPL).
One important discovery is I need a module system. This project rapidly hit 1000 lines of code and doing that in one file is futile! I'd been thinking about this for a while because I want AIs to write their own tools as they solve problems, so I guess this has now bubbled up the priority list.
Oddly, alists may play an important role in this module system! More to come...
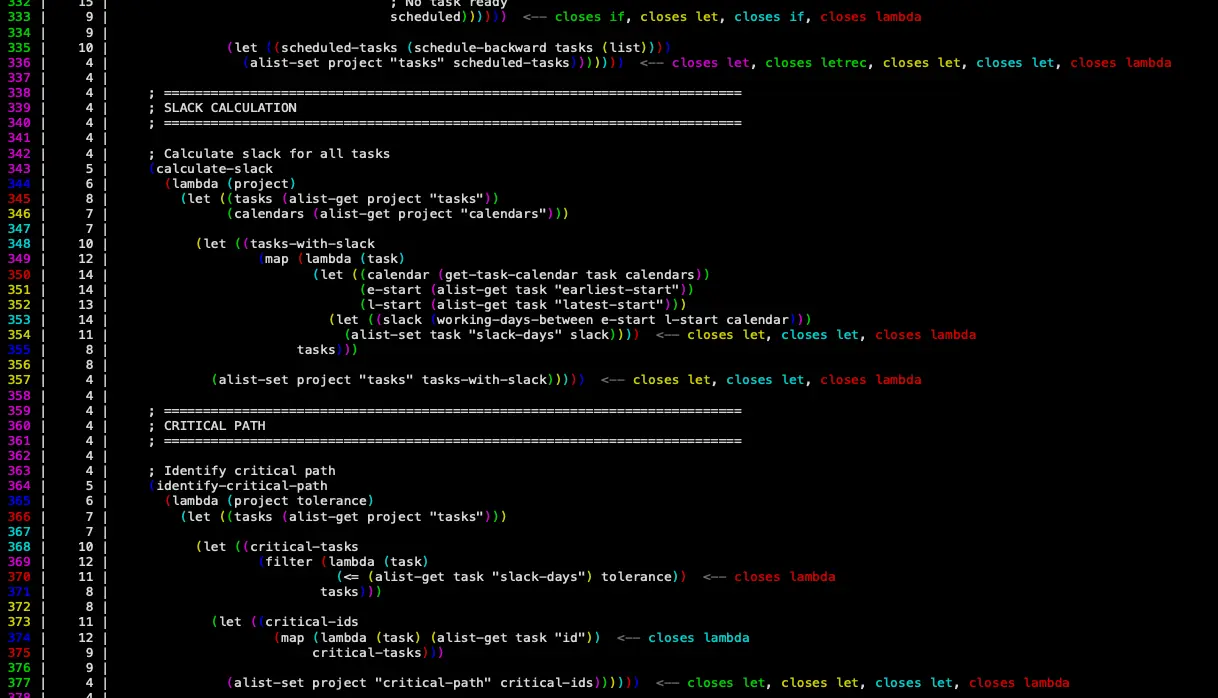
The major problem, however, is finding LLMs can't debug the closing parens for Lispy code. They can't work out how many closing parens they're looking at when they come to debug code, if they didn't one-shot working code.
I thought I might simply be able to fix this by improving the AIFPL parser errors. The new errors use line and column numbers and provide more code context. Worked wonders for me debugging problems, but not so much for Claude.
My theory is LLMs are really bad at working backwards from where they're told the problem has been found to where the problem actually occured. I think I need to experiment more with the tool error messages!
What I did also realize was that debugging this stuff is quite tricky, even with a good editor that matches parens. Claude suggested we build a tool that can analyze expression depth. I suggested we annotate where special forms close out, add line numbers, and add some colour.
The tool took about an hour to build and is in tools/aifpl-cheker. This seems very promising, although it will need more work. I'm thinking it needs to be bolted into Humbug's UI and tools somewhere too.